Word and Sentence Length Search
In order to find syntactic and text units of a certain length, i.e. words, chunks or sentences, one can use the function length().
Syntax
The first two arguments min_length and max_length are used to set minimum and maximum length (in characters), respectively. The argument min_length is required, while the max_length is optional. If max_length is not specified, the function matches arguments that consist of at least min_length characters.
Example
In order to specify a unit of length, users may use the optional named parameter count:= that takes the following values:
Value |
Explanation |
character |
length is calculated in symbols (default value) |
token |
length is calculated in tokens (both words and punctuation) |
word |
length is calculated in words |
punctuation |
sets the number of punctuation signs |
Example
Note: for more information about the entity() and keyword() functions used in the example above see Search for objects extracted by other text analysis nodes.
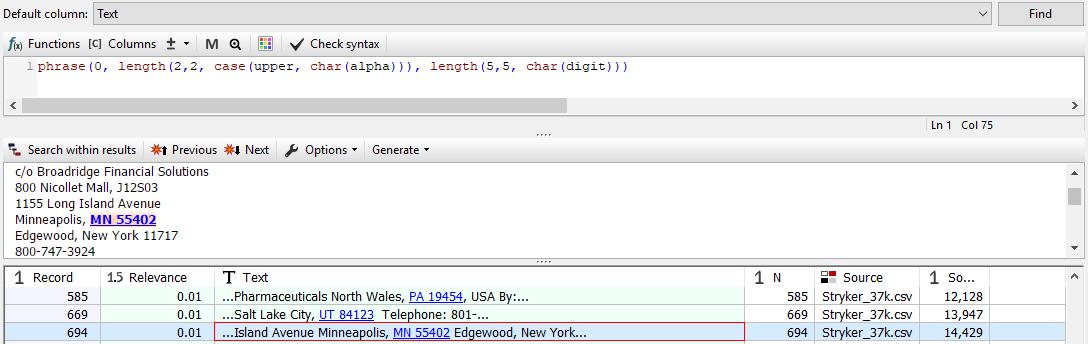
Task Example: Find USA Postal Codes
phrase(0, length(2,2, case(upper, char(alpha))), length(5, 5, char(digit))) matches two letters in upper case followed by 5 digits, that are often postal codes in the USA (CA 92108, NY 10004, TX 77002, etc.).